This is the first of a series of posts in which I’ll be exploring concepts taught in Andrew Ng’s Introduction to Machine Learning course on Coursera. As a CS student, I enjoyed doing odd or extra things with my assignments — I found it added a greater challenge and allowed me to learn outside the scope of the class in a well-structured way. So, as I progress through this course, I’ll be posting another take on the coursework in Python, using a Jupyter notebook.
Each post will begin with an implementation of the algorithm for the week, tracking closely to the requirements and terminology of the assignment, but trading Octave/MATLAB functions for standard Python data science tools, and then conclude by exploring what the same algorithm would look like built in Tensorflow. I’ll also be using different data sets, to make things a bit more interesting, and to avoid duplicating material from the course.
The first programming assignment covers linear regression. Linear regression attempts to fit a line of best fit to a data set, using one or more features as coefficients for a linear equation. Here, I’ll discuss:
- Loading, manipulating and plotting data using numpy and matplotlib
- The hypothesis and cost functions for linear regression
- Gradient descent with one variable and multiple variables
- Feature scaling and normalization
- Vectorization and the normal equation
- Linear regression and gradient descent in Tensorflow
In this post, I’m using the UCI Bike Sharing Data Set.
Loading and Plotting Data
For the first part, we’ll be doing linear regression with one variable, and so we’ll use only two fields from the daily data set: the normalized high temperature in C, and the total number of bike rentals. The values for rentals are scaled by a factor of a thousand, given the difference in magnitude between them and the normalized temperatures.
import pandas as pd
data = pd.read_csv("./data.csv")
temps = data['atemp'].values
rentals = data['cnt'].values / 1000
The plot reveals some degree of correlation between temperature and bike rentals, as one might guess.
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(temps, rentals, marker='x', color='red')
plt.xlabel('Normalized Temperature in C')
plt.ylabel('Bike Rentals in 1000s')
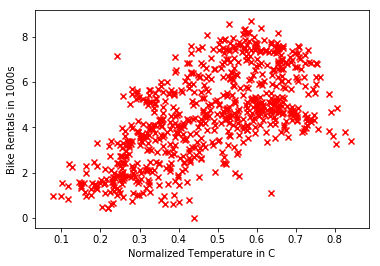
Simple Linear Regression
We’ll start by implementing the cost function for linear regression, specifically mean squared error (MSE). Intuitively, MSE represents an aggregation of the distances between point’s actual y value and what a hypothesis function $h_\theta(x)$ predicted it would be. That hypothesis function and the cost function $J(\theta)$ are defined as
\begin{align}
h_\theta(x) & = \theta_0 + \theta_1x_1 \\
J(\theta) & = \frac{1}{2m}\sum\limits_{i = 1}^{m}(h_\theta(x^{(i)}) - y^{(i)})^2
\end{align}
where $\theta$ is a vector of feature weights, $x^{(i)}$ is the ith training example, $y^{(i)}$ is that example’s y value, and $x_j$ is the value for its jth feature.
import numpy as np
def compute_cost(X, y, theta):
return np.sum(np.square(np.matmul(X, theta) - y)) / (2 * len(y))
Before computing the cost with an initial guess for $\theta$, a column of 1s is prepended onto the input data. This allows us to vectorize the cost function, as well as make it usable for multiple linear regression later. This first value $\theta_0$ now behaves as a constant in the cost function.
theta = np.zeros(2)
X = np.column_stack((np.ones(len(temps)), temps))
y = rentals
cost = compute_cost(X, y, theta)
print('theta:', theta)
print('cost:', cost)
theta: [ 0. 0.]
cost: 12.0184064412
We’ll now minimize the cost using the gradient descent algorithm. Intuitively, gradient descent takes small, linear hops down the slope of a function in each feature dimension, with the size of each hop determined by the partial derivative of the cost function with respect to that feature and a learning rate multiplier $\alpha$. If tuned properly, the algorithm converges on a global minimum by iteratively adjusting feature weights $\theta$ of the cost function, as shown here for two feature dimensions:
\begin{align}
\theta_0 & := \theta_0 - \alpha\frac{\partial}{\partial\theta_0} J(\theta_0,\theta_1) \\
\theta_1 & := \theta_1 - \alpha\frac{\partial}{\partial\theta_1} J(\theta_0,\theta_1)
\end{align}
The update rule each iteration then becomes:
\begin{align}
\theta_0 & := \theta_0 - \alpha\frac{1}{m} \sum_{i=1}^m (h_\theta(x^{(i)})-y^{(i)}) \\
\theta_1 & := \theta_1 - \alpha\frac{1}{m} \sum_{i=1}^m (h_\theta(x^{(i)})-y^{(i)})x_1^{(i)} \\
\end{align}
See here for a more detailed explanation of how the update equations are derived.
def gradient_descent(X, y, alpha, iterations):
theta = np.zeros(2)
m = len(y)
for i in range(iterations):
t0 = theta[0] - (alpha / m) * np.sum(np.dot(X, theta) - y)
t1 = theta[1] - (alpha / m) * np.sum((np.dot(X, theta) - y) * X[:,1])
theta = np.array([t0, t1])
return theta
iterations = 5000
alpha = 0.1
theta = gradient_descent(X, y, alpha, iterations)
cost = compute_cost(X, y, theta)
print("theta:", theta)
print('cost:', compute_cost(X, y, theta))
theta: [ 0.94588081 7.50171673]
cost: 1.12758692584
We can examine the values of $\theta$ chosen by the algorithm using a few different visualizations, first by plotting $h_\theta(x)$ against the input data. The results show the expected correlation between temperature and rentals.
plt.scatter(temps, rentals, marker='x', color='red')
plt.xlabel('Normalized Temperature in C')
plt.ylabel('Bike Rentals in 1000s')
samples = np.linspace(min(temps), max(temps))
plt.plot(samples, theta[0] + theta[1] * samples)
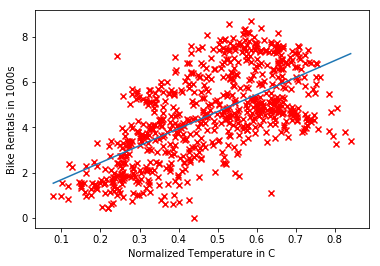
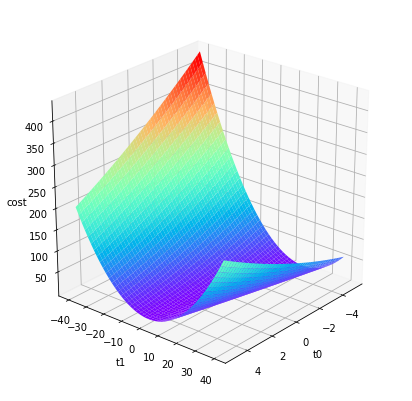
A surface plot is a better illustration of how gradient descent approaches a global minimum, plotting the values for $\theta$ against their associated cost. This requires a bit more code than an implementation in Octave / MATLAB, largely due to how the input data is generated and fed to the surface plot function.
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
Xs, Ys = np.meshgrid(np.linspace(-5, 5, 50), np.linspace(-40, 40, 50))
Zs = np.array([compute_cost(X, y, [t0, t1]) for t0, t1 in zip(np.ravel(Xs), np.ravel(Ys))])
Zs = np.reshape(Zs, Xs.shape)
fig = plt.figure(figsize=(7,7))
ax = fig.gca(projection="3d")
ax.set_xlabel(r't0')
ax.set_ylabel(r't1')
ax.set_zlabel(r'cost')
ax.view_init(elev=25, azim=40)
ax.plot_surface(Xs, Ys, Zs, cmap=cm.rainbow)
Finally, a countour plot reveals slices of that surface plot in 2D space, and can show the resulting $\theta$ values sitting exactly at the global minimum.
ax = plt.figure().gca()
ax.plot(theta[0], theta[1], 'r*')
plt.contour(Xs, Ys, Zs, np.logspace(-3, 3, 15))

Multiple Linear Regression
First, we reload the data and add two more features, humidity and windspeed.
Before implementing gradient descent for multiple variables, we’ll also apply feature scaling to normalize feature values, preventing any one of them from disproportionately influencing the results, as well as helping gradient descent converge more quickly. In this case, each feature value is adjusted by subtracting the mean and dividing the result by the standard deviation of all values for that feature:
$$
z = \frac{x - \mu}{\sigma}
$$
More details on feature scaling and normalization can be found here.
def feature_normalize(X):
n_features = X.shape[1]
means = np.array([np.mean(X[:,i]) for i in range(n_features)])
stddevs = np.array([np.std(X[:,i]) for i in range(n_features)])
normalized = (X - means) / stddevs
return normalized
X = data.as_matrix(columns=['atemp', 'hum', 'windspeed'])
X = feature_normalize(X)
X = np.column_stack((np.ones(len(X)), X))
y = data['cnt'].values / 1000
The next step is to implement gradient descent for any number of features. Fortunately, the update step generalizes easily, and can be vectorized to avoid iterating through $\theta_j$ values as might be suggested by the single variable implementation above:
$$
\theta_j := \theta_j - \alpha\frac{1}{m} \sum_{i=1}^m (h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}
$$
def gradient_descent_multi(X, y, theta, alpha, iterations):
theta = np.zeros(X.shape[1])
m = len(X)
for i in range(iterations):
gradient = (1/m) * np.matmul(X.T, np.matmul(X, theta) - y)
theta = theta - alpha * gradient
return theta
theta = gradient_descent_multi(X, y, theta, alpha, iterations)
cost = compute_cost(X, y, theta)
print('theta:', theta)
print('cost', cost)
theta: [ 4.50434884 1.22203893 -0.45083331 -0.34166068]
cost 1.00587092471
Unfortunately, it’s now more difficult to evaluate the results visually, but we can check them a totally different method of calculating the answer, the normal equation. This solves directly for the solution without iteration specifying an $\alpha$ value, although it begins to perform worse than gradient descent with large (10,000+) numbers of features.
$$
\theta = (X^TX)^{-1}X^Ty
$$
from numpy.linalg import inv
def normal_eq(X, y):
return inv(X.T.dot(X)).dot(X.T).dot(y)
theta = normal_eq(X, y)
cost = compute_cost(X, y, theta)
print('theta:', theta)
print('cost:', cost)
theta: [ 4.50434884 1.22203893 -0.45083331 -0.34166068]
cost: 1.00587092471
The $\theta$ values and costs for each implementation are identical, so we can have a high degree of confidence they are correct.
Linear Regression in Tensorflow
Tensorflow offers significantly higher-level abstractions to work with, representing the algorithm as a computational graph. It has a built-in gradient descent optimizer that can minimize the cost function without us having to define the gradient manually.
We’ll begin by reloading the data and adapting it to more Tensorflow-friendly data structures and terminology. Features are still normalized as before, but the added column of 1s is absent: the constant is treated separately as a bias variable, the previous $\theta$ values are now weights.
import tensorflow as tf
X = data.as_matrix(columns=['atemp', 'hum', 'windspeed'])
X = feature_normalize(X)
y = data['cnt'].values / 1000
y = y.reshape((-1, 1))
m = X.shape[0]
n = X.shape[1]
examples = tf.placeholder(tf.float32, [m,n])
labels = tf.placeholder(tf.float32, [m,1])
weights = tf.Variable(tf.zeros([n,1], dtype=np.float32), name='weight')
bias = tf.Variable(tf.zeros([1], dtype=np.float32), name='bias')
The entire gradient descent occurs below in only three lines of code. All that’s needed is to define the hypothesis and cost functions, and then a gradient descent optimizer to find the minimum.
hypothesis = tf.add(tf.matmul(examples, weights), bias)
cost = tf.reduce_sum(tf.square(hypothesis - y)) / (2 * m)
optimizer = tf.train.GradientDescentOptimizer(alpha).minimize(cost)
The graph is now ready to use, and all the remains is to start up a session, run the optimizer iteratively, and check the results.
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1, iterations):
sess.run(optimizer, feed_dict={
examples: X,
labels: y
})
print('bias:', sess.run(bias))
print('weights:', sess.run(weights))
bias: [ 4.50434685]
weights: [[ 1.22203839]
[-0.45083305]
[-0.34166056]]
The bias and weight values are identical to the $\theta$ values calculated in both implementations previously, so the Tensorflow implementation of the algorithm looks correct.
You can find the IPython notebook for this post on GitHub.